In the past few years, I’ve been helping AI companies turning their great AI technology into products users will want and use. During these experiences, I’ve been using AI more and more to evolve from a product designer to a product builder, ultimately aiming to build features on my own, leveraging AI.
When Devin by Cognition Labs got announced, I knew I had to try it: an AI product, apparently a very good one, that could also help me build even more!
Introduced by an early investor to Scott, the Cognition Labs CEO, I explained my use case: being able, as a product guy, to build from scratch a web app with the help of Devin. Scott found this experiment pretty cool and introduced me to Silas, who manages the early access process. They were both very candid and totally transparent:
I agree that this use case is what we all secretly dream of. I will warn you that the intended user of Devin is an engineer because it still needs technical guidance and tasks of smaller scopes – it usually can't quite do full projects yet. That being said, I'd love for you to give it a try.
As we discussed, building great products is about striving for the best possible user experience — in this case, create a development tool so sophisticated yet simple that even a product manager can use to become a product builder.
I truly admired Scott and Silas's willingness to take on the challenge so early and allow me to push the boundaries of what Devin can do.
Below is my in-depth, unbiased report of my experience with Devin.
Notes
Each section is structured with a detailed description of my journey using Devin, along with feedback noted by 💡 and bugs indicated by 🐛 for easy reference.
Some comments are speculative, as I don't have full insights into how Devin is built internally. It’s likely that some conclusions are wrong due to inaccurate guesses.
Devin is a unisex given name, I will refer to Devin as 'it', as encouraged by Cognition Labs.
Experiencing the product
Information architecture
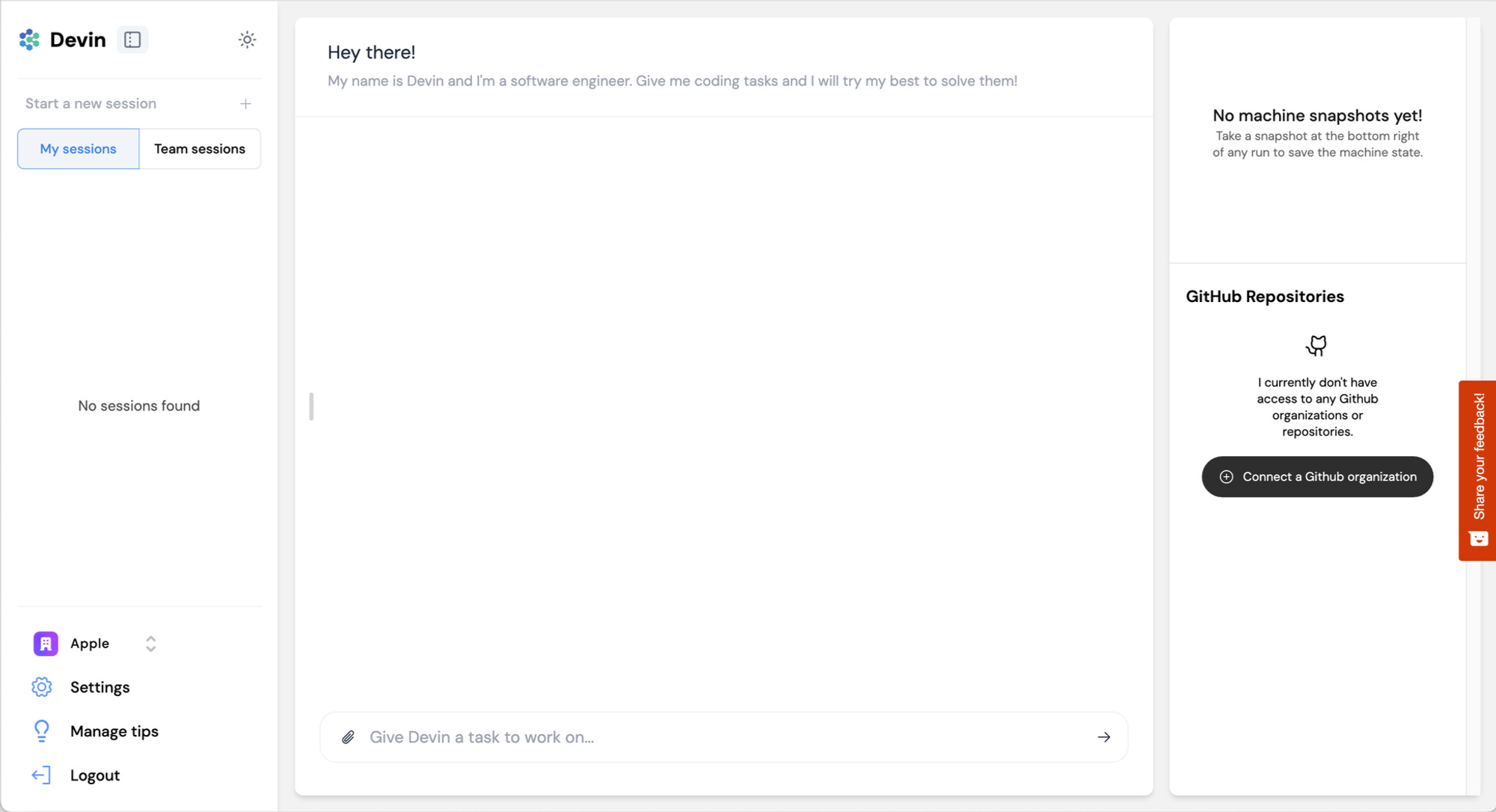
There 3 main areas in Devin:
The chat sessions with Devin (Chat) on the left panel, along side with Settings and a switch between Personal and Organization account
The selected chat session in the middle
Devin’s Workspace on the right
The Devin app
This is a pretty typical structure for a chat app or AI assistant like ChatGPT or Claude. The novelty here is Devin’s Workspace with its 4 tabbed views:
Shell: Devin’s terminal where it interacts with development environment and server systems
Browser: the browser used by Devin to check links you send or test the code as applicable
Editor: Devin’s editor used to generate code
Planner: a simple to-do list used by Devin to plan what to do and track progress
Devin’s Workspace: Shell and Planner
The Editor has additional capabilities such as code diffs from previous state (difficult to review due to small viewing area), a “Global Work View” (with all files modified by Devin, little buggy/unfinished), code download and an expanded version for better file navigation and larger viewing area:
The concept of the Devin’s Workplace and its 4 views is well thought and is enabling the “humanization” of Devin AI. The experience is very much what you have when you talk to a developer: they have a terminal, a browser to research or test the product, a code editor, and (hopefully) a to-do list. This approach makes the product extremely usable from the get-go even for non-developers (yet familiar with the development process) like me; of course to make Devin even more accessible to the masses in the future, this will have to evolve, but I think it’s not the goal at the moment.
Another layout is available by pressing the Grid button, that takes the 5 views (Chat + Workspace) and lays 4 of them in a grid:
💡 I found this grid layout a little weird. I assumed that it would layout the 4 tabs in Devin’s Workspace in the grid, but instead the Planner is replaced by the Chat, now included in Devin’s Workspace container (the Chat is separated in the non-grid layout).
However, I can’t chat with Devin - perhaps it represents the chat Devin sees, but what’s the use for it? I guess it all depends on what this layout is designed for. I’d assume it’s to monitor Devin’s work, so I’d stick to the 4 views of Devin’s Workspace: if I want to chat, I can switch back to the non-grid view.
I haven’t played much with the Organization type of account, but as you can see here there are two tabs for sessions: “My sessions” and “Team sessions”.
Devin for Organizations
💡 From a hierarchy perspective I’d have probably moved the tab control above the “Start a new session”: from a user flow perspective, you first pick the type of session and then you create a session within your selection. Alternatively, I’d use “Start a new team session” when Team sessions tab is selected to improve clarity about where the session will be shared.
Meta awareness
During my tests, it was not clear to me if Devin has any awareness of the app structure or its features. In other words, I couldn’t confirm that for example Devin know about the 4 tools it has available (Shell, Browser, Editor, Planner) and can refer to it while chatting with me. For sure, Devin didn’t know about a couple of features the app has and I asked about (upload playbook and machine snapshot, will cover this in a bit).
I think this is a pretty important aspect that is currently missing or should be improved if already there, as it could enhance even further the experience of interacting with Devin as a “real” developer.
For example, I was trying to go past a situation where Devin kept saying that everything was working in its setup, but it wasn’t in the deployed code; to debug it I asked to show me a specific step of the workflow being tested in its browser, so I could compare it with mine. Basically I was expecting to check the Browser tab in Devin’s Workspace and see a specific web page “loaded” (in reality, those are screenshots of a browser view, not the actual browser).
Devin kept describing what it was on the browser, but it was not able to show me that page in the browser itself. At some point I had the feeling Devin was only describing what it was supposed to be displayed in that page based on the specs I provided rather than describing an actual page itself.
After insisting several times asking to go through the flow again and stop at the point I was interested in, I could see the page in the browser, but my sense is that that happened only because Devin understood it had to reproduce certain steps and as a consequence the browser was update.
As you can see here, Devin has a “behind the curtains” knowledge that a browser is being used (”Clicked on ‘Create New Prompt’ and observed the modal opening in the browser”); but it doesn’t seem to connect that when chatting with me.
Technically the end result was the same, i.e. I was ultimately able to see the page in the browser, but I had to modify my “prompt”/instruction to make it happen and I could only do as I somehow guessed (maybe) what was actually going on and how I could trick Devin to do it. Many users would have probably given up at this point.
💡 Giving Devin awareness of what’s exposed to the user, e.g. the Workspace with its tools, the features of the product, the available settings, etc. would allow Devin to better interact with the user and follow more closely their instructions. It should be easy to provide such knowledge through a mix of prompting, RAG (Retrieval-Augmented Generation) methodologies, and whatever is currently done to tune the model.
Following Devin’s work
A fascinating part of Devin’s user experience is the ability to watch its progress live as it plans and codes.
By setting the “Following” switch to ON, you can see Devin’s Workspace switching between the 4 tabs - Shell, Browser, Editor, Planner - as it uses them in real time.
Unfortunately, at first I didn’t understand the purpose of the “Following” switch, despite the tooltip. The label “Following” wasn’t conveying much to me, and even the tooltip wasn’t adding much as it was just re-using “Follow”. I might have been distracted when I first saw it, but that’s what happened, so I’m reporting it. Just set it to ON, as it’s actually fun and useful to see what Devin is working on.
💡 A simple fix to this potential UX issue is to update the label and make the tooltip text a little more verbose, explaining what’s going to happen in a compelling way. A little more sophisticated approach would be to include this feature in the onboarding. I also don’t recall for sure, but I think by default the switch is set to OFF. I’d start with ON as default, so the user can fully experience the product right away and has the option to turn it off, if not interested.
You can also see where Devin is at the moment, by looking at Devin’s logo next to the tab where it is active, in this case the Shell:
💡 It took me a bit to realize this behavior. Maybe it’s because of the position of the logo (left to the tab label) that is not super noticeable and not directly, at least for me, implying a correlation between logo and tab; there is also no visual separator between tabs, making the association with the logo more difficult to notice. Or maybe it’s because it’s a logo vs. an avatar (what I think it should be) - a subtle difference but critical in associating Devin visual representation to its movements within the Workspace. To minimize the changes though, I’d start by simply moving the logo to the top right of the tab label: I think I’d find it more noticeable and it would have given me the sense that Devin “is on that tab now”.
🐛 Another small detail is that the logo does not change opacity like the associated tab label does when the user switches tabs; this inconsistency visually impacts the grouping of the tab and logo and I guess was part of my confusion.
In case you “stepped out” and want to trace back Devin’s activities, you can slide the bar at the bottom of Devin’s Workspace or use the Previous/Next buttons. While navigating in time Devin’s Workplace, the chat is automatically scrolled to the messages exchanged before triggering the activities currently displayed, providing the context of what you see in Devin’s Workspace.
Devin’s work timeline
Beside the few issues I’ve pointed out and some stuff that could be improved, I’ve found this novel design and implementation a very good addition to the UX patterns of AI assistants.
Chat UI and UX
Human-Like Chat Experience
Another aspect that positively surprised me is the choices Cognition Labs made with regard to chatting with Devin.
Chat UX for AI assistants kinda standardized (i.e. everyone else copied) after OpenAI introduced ChatGPT:
User sends a message to the AI assistant
A UI element of the AI assistant starts pulsating, providing visual feedback to indicate thinking or activity
The AI assistant starts streaming an answer, character after character
The user must wait the AI assistant to finish their sentences before sending the next message
User can click a button to interrupt the streaming and send their message without waiting
Devin is different. It might be because Cognition Labs wanted to emulate a human engineer chatting with you or simply because they preferred an evolution of the “human-like” chat UX:
User sends a message to Devin
Also here a pulsating UI element indicates that Devin is doing something, but in Devin’s case it is followed by some text detailing what task Devin is working on. If Devin is not doing anything at the moment, “Devin is thinking…” is displayed:
Else, the current task Devin is working on is described:
Instead of streaming an answer, Devin follows the standard human chat design where we see that “Devin is typing…” and the entire answer is posted at once.
The user doesn’t have to wait to send the next message or click buttons to interrupt Devin: they can simply send another message to Devin like you would when chatting with another human in a chat app. I’ve found the clue “(won’t interrupt Devin)” clever and certainly needed to encourage the more natural human-human vs. human-AI assistant chat interaction we got “trained” to follow in the past couple of years.
I think this approach is a refreshing one for AI assistants, mimicking very well the common UX you experience when using chat apps, while adapting to the AI assistant case. I personally never found the one-message-only-unless-you-interrupt-streaming experience of AI assistants very natural, despite using it daily for 2 years now. As humans, it often happens to send multiple messages in a row to convey something or simply when we want to add something new that came up to mind after the first message. It also feels rude to interrupt someone with a button 🙂.
Seeing an answer being streamed “as it’s typed” is also not something natural and it has UX implications: the screen starts scrolling while you read and for long messages you need to stop the scrolling or event scroll back to the top to start reading. I guess originally it was an “hack” to mask the slowness of the models in generating responses, especially the long ones. I think this issue might go away with the inference speed we have seen for example with Groq, but independently another angle is to reduce verbosity: I noticed that Devin’s answers are always very concise and to the point, effectively reducing the latency perception and honestly improving overall interaction quality. Also, UI clues like “Devin is typing…” are helping making the experience extremely natural.
I believe more AI assistants will go back to this AI-adjusted human-like UX, but in the meantime, great job Cognition Labs!
In-flow agent updates
Devin introduces a way to share AI agent progress in a minimalist yet effective style: intermediate tasks are displayed along with the chat messages as Devin completes them:
I liked this approach quite a bit and found the visual hierarchy it provides very effective for quickly checking or skipping intermediate tasks when reading messages with Devin.
File and data sharing
Lastly, you can upload a file, share a playbook (I’d use “share” vs. repeating “upload” as in current UI), and provide credentials to Devin:
Uploading files is standard, and unfortunately you have to use that flow to upload screenshots too. I’m used to just screenshot a portion of the screen and paste in messaging apps (including AI assistants), while here I have to open the Preview app, paste the screenshot, save it as file, go back to Devin, click the 📎, click Upload File, click on the opened modal, find the file in the Finder, select it, click on Open. 10 steps vs. 1. I assume this capability will be added shortly.
“Upload Playbook” is something very recent and I didn’t try it yet. There is not much information about it: I don’t know how it works, what can be done with it, what format the playbook should have, etc.
When asked about this new feature, Devin claimed it knew about it, but never provided me any info 🙂. I think that these confident answers are just LLM-driven hallucinations based on common knowledge around these topics (and they should be limited):
“Provide Credentials” is instead straightforward and nicely designed, conveying that critical information can be securely shared with Devin vs. just using plain text message. It’s a nice touch.
Interacting with Devin
Maybe it’s just me, but I purposely decided to treat Devin not as an AI that just codes, but as an engineer I’d talk to, engaging in clarification questions and brainstorming sessions; for example:
I asked motivations behind choosing a particular stack of the web app I wanted Devin to develop
I discussed UI libraries selection, proposing an alternative that Devin didn’t know about but investigated
I brainstormed on user authentication options, agreeing on selecting the simplest option in order to get to MVP faster
The conversations were very natural, again presented with the voice of a developer; as mentioned, I didn’t find them unnecessarily verbose like sometimes I find ChatGPT or Claude. Kind of what you would expect from a developer 🙂. I don’t know if this is the result of specific prompting or training, but the result was good and pleasant.
I did find the tone sometimes to be a little “submissive” or “subservient” though, which I don’t think it’s necessary.
💡 If some prompting/training on the tone is performed (and I think it should), I’d attempt to recreate more of a peer-to-peer relationship rather than a senior-to-junior (engineer-to-engineer) or assistant-like (product-to-engineer) where Devin is considered “subordinate”. From a product branding perspective, I think positioning Devin as a peer might increase user confidence. And with model improvements, we all know Devin will be soon better than us anyway 😄!
On the flip side, while I was putting trust in Devin as I would in a “human” engineer, I was still worried about going back and forth on some topics or suggesting changes. Probably I know too much about LLMs or how these agentic systems work, but I felt compelled to stay on course and hold some of my comments or requests until Devin was done with its current tasks: I just wanted to see the first version of the product and I figured minimizing changes or avoiding tangents would have helped that.
In general, this is a good thing also in real world 🙂, but, with Devin, it was the UX “forcing” this behavior: Devin would initiate new background tasks, some requested and some not, even while we were still chatting.
I think users will get used to and appreciate this attempt at “super-efficiency”; the only behavior I think it’s important to tweak is when Devin ask the approval to proceed and it starts anyway on the task without waiting for an answer (I’ll share some example I encountered later on).
💡 It’s possible that Devin is not fully “conscious” it is asking a question to the user and therefore it just starts working on a task once it knows what to do, as it happens in other cases. I think it’s important to distinguish when a user input is requested/required to make sure the experience remains smooth.
Overall, interacting with Devin was one of the first experiences with AI assistants that felt extremely natural and engaging, striking the right balance and fostering an effective communication dynamic.
Product branding
I think my decision to treat Devin as an actual engineer and not an AI assistant was also driven by the detailed work on product branding that Cognition Labs implemented throughout the product.
Devin is not presented as a Copilot or as an AI assistant, but as a Developer.
The product branding is explicit in the browser tab label:
or at the start of each chat session:
💡 Keeping consistent branding is important: first “the Developer” is used, then “software engineer”; they are of course interchangeable but I’d pick one and stick to it.
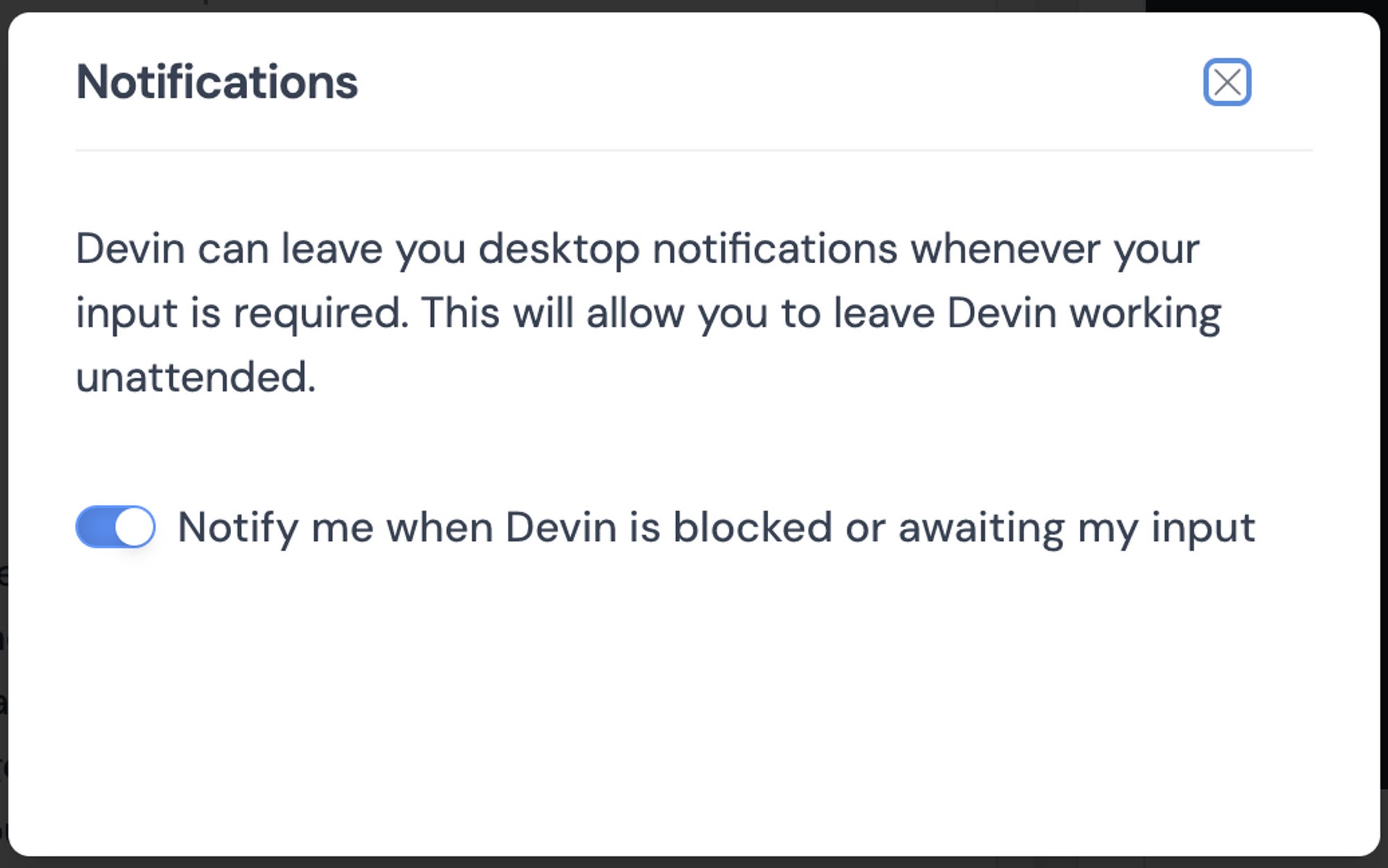
As if you were chatting with a developer, you can get notifications from Devin:
💡 The copy is clear, again aiming to personalize Devin. But if the goal is to present Devin as a regular developer, I’d suggest making the message feel even more "human." For instance, instead of using "leave desktop notifications," "working unattended," etc., the interaction can be described as one you might have with any developer: "Enable notifications to receive progress updates from Devin or questions Devin might have for you. This allows Devin to work on tasks independently, while keeping you informed." This adjustment would enhance brand consistency; otherwise, the message is certainly clear.
🐛 Unfortunately, notifications never worked for me (I’m on MacOS, Chrome). I checked browser settings and Devin settings a few times, but I couldn’t get it to work. This was a pretty important UX issues as I think the async interaction is a major component of the success of Devin, but I’m sure it will be resolved in the future and likely limited to setup like mine (i.e. I’m sure it works for others).
These are all details, but I think they are important to shape the way people use and interacts with AI products, no matter what experience you want to present.
Initial setup
To start working with Devin, it has to setup its development environment.
It does that based on your initial inputs and the process is completely autonomous. Even in case of installation errors, Devin figures out how to correct and go past them. You can follow the process in the Workplace area or with Devin’s updates in the chat.
While smooth as an experience, it’s still time/resource consuming, as at each session you have to repeat the process. To me, it seems unnecessary to install each time the same packages, considering you are probably working with a similar tech stack every time. Some packages are preinstalled, like python (even if I believe the very first time I worked with Devin it had to install it, but not sure); others, even if popular, are installed each time as Devin confirmed:
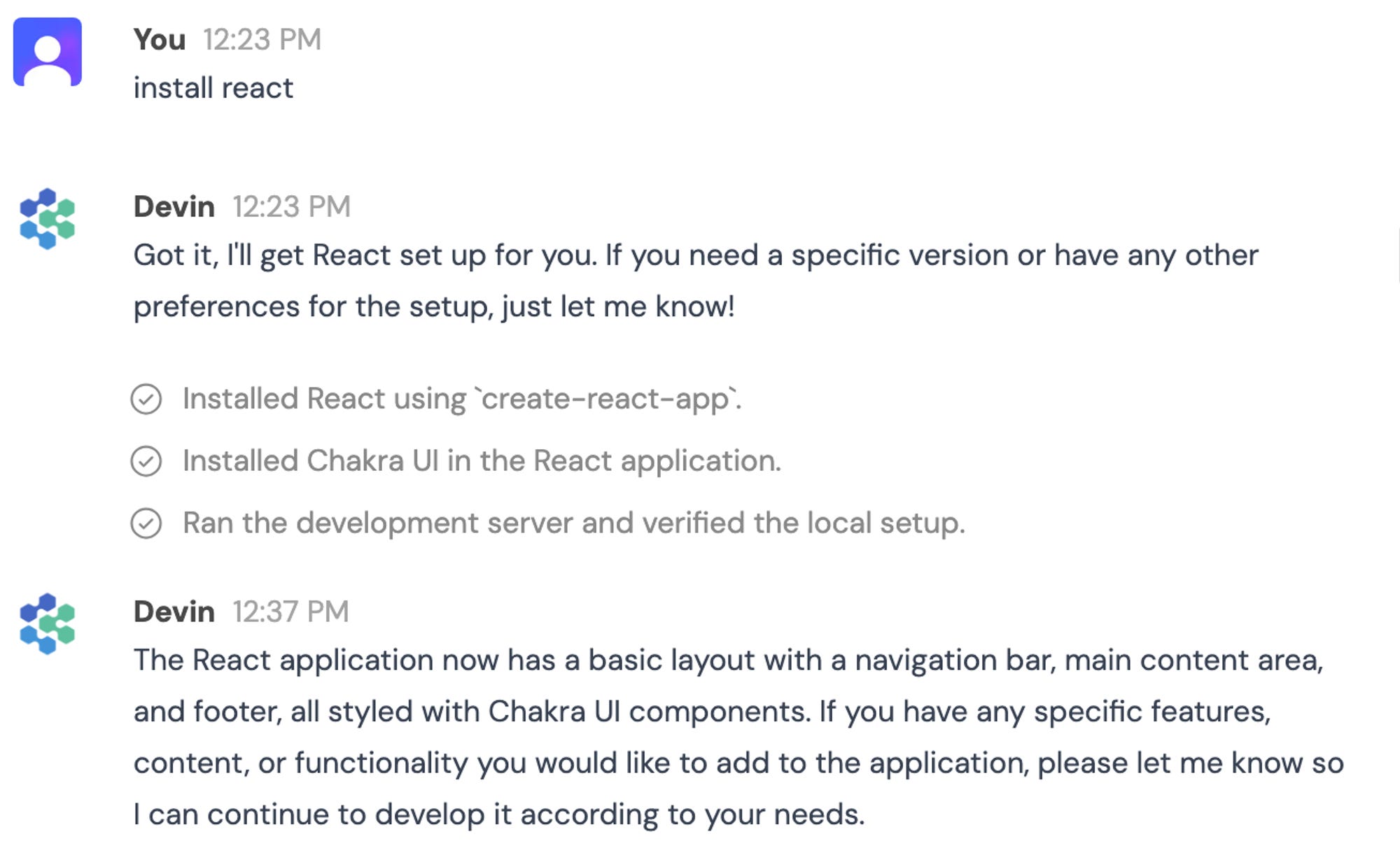
For example, each time you want to use React, you have to install it:
As you can see from timestamps, it took 14 minutes (testing was included, Chakra UI was installed too even if not requested, I assume to run the tests as a “demo app” was built to check everything was working):
Test web app to verify Reach installation
💡 Automatically after a few sessions or through an onboarding conversation, I’d allow users to configure machines and share them with the rest of the team, so that similar tasks can be performed immediately. At the end, that’s what happens with human engineers - a team has installed similar packages if they are working on the same projects. Possibly that already works when you sync your Github account, but I didn’t try that.
I believe that there is now some sort of hack for this situation, as the Cognition Labs team introduced a process to create machine snapshots just a few days ago:
When clicking on it, this modal pops up:
If you are not familiar with the concept of machine snapshot, this message might not be super clear, especially in the context of how to use it with Devin.
💡 Not all the developers are necessarily familiar with machine snapshot, typically a backend/system admin concept. It would be good to explain what can be done in the context of a new session using such snapshot and the use cases for Devin.
I did ask Devin if it knew specifically about the machine snapshot feature in Devin product, but it didn’t have any answer, confirming the lack of meta awareness discussed above:
This copy is also interesting:
Snapshot description (Devin needs this to understand the snapshot contents)
💡 It’s not clear what type of information would be useful to provide to Devin. Is this possibly something that can be AI-generated by Devin itself, to be modified as needed? Or at least providing a description example or bullet list would be helpful.
I personally read that text after creating a couple of snapshots and I always left that description empty - Devin didn’t force me to enter it and I guess it worked fine when restoring it.
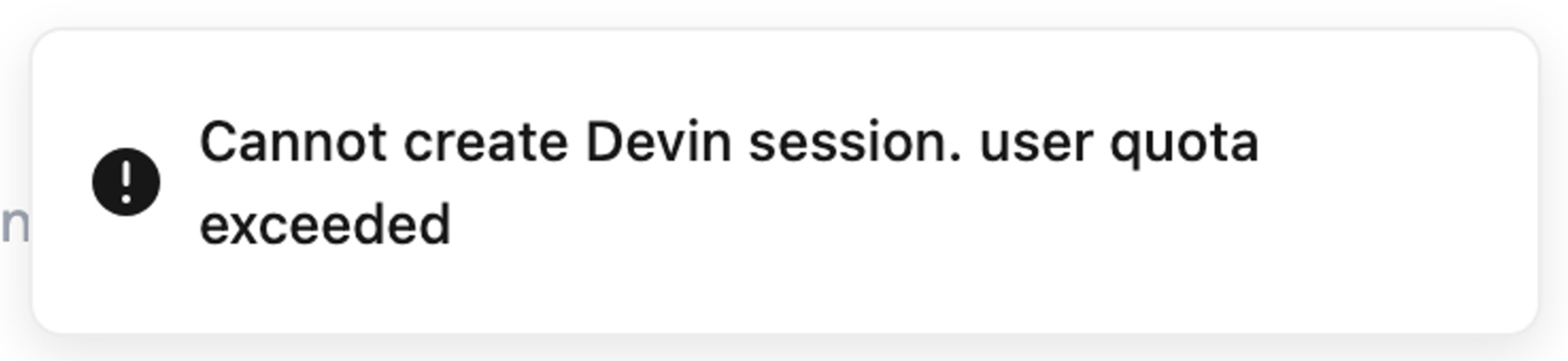
While testing a few new sessions with the saved snapshots, I ended up getting this error message:
💡 It would be useful to know when as a user I’ll be able to create a new Devin session. At a certain time later today? End of the day? End of the week? It also seems random: I got the message, waited a bit, restarted using it, but then I got blocked again the following day despite no new usage. I think it’s just beta experience. There is also a small typo (the u in “user quota” should be capitalized)
Considering I exceeded the user quota, I tried to see if I could ask Devin to change the snapshot initially used for that session (labeled “React”) with another one that I created (”WebApp - 1”). Initially, Devin acted as if it understood that creating a machine snapshot was a feature of Devin itself. This was contradicting what Devin told me previously about not having any information for the machine snapshot feature, suggesting to read the documentation. I kept going.
Devin asked me for the name of the snapshot to be used, I provided it and it claimed it would start a new session replacing the current one:
🐛 Here is an example where Devin just started executing an action without waiting for me to respond to the question it asked me.
After some back and forth where Devin thought it was working on restarting the session with the right snapshot and successfully completed the task, I realized that it had no idea of what was going on. I asked if it could provide the link to the published web app from the “WebApp - 1” session, but instead it ended up not finding any deployment server and simply publishing the test React web app created in “React” session, the original snapshot this session started with.
With this test, I think I proved two points:
The machine snapshot creation is really a fully standard snapshot of the machine, preserving its configuration, code, deployment information, etc. So standard definition I’d say.
💡 For an AI conversational product like Devin, I’d be curious to know if also the chats from the previous session are snapshotted and provided as a context for the new session. I think it depends on the use cases to use snapshots in Devin and on the actual design of Devin conversational experience: is the snapshot used to continue a session or as a fresh setup for a brand new session? how big is the context window? is the context window used to carry the conversation on? is some information extracted from chats and maintained as context to be accessed as needed?
Devin has no idea about Devin as a product, i.e. it doesn’t have information about its features or access to meta-information like the list of snapshots created in various chat sessions.
💡 As discussed before, I think this is a missed opportunity or better a feature to be released at some point. As part of the onboarding experience, users should be able to ask Devin questions about the product; Devin, as a developer, should also understand the user's context within the product (e.g. list of snapshots created) while interacting with them, just as a real developer would.
Going back to the original point of having to install the same packages each time, I guess the current solution is to configure a machine with all the packages you typically use and create a snapshot of that to be used each time. I don’t know if this is the designed experience or just an hack I came up with. You need to be careful though, as sometimes Devin starts installing packages simply if you ask if they are available, or additional packages only to test if the requested package is installed properly. For example here I asked to install React and I got Chakra UI too:
I resolved this by explicitly telling Devin what to do and not do (e.g. “install React and nothing else”).
Once your machine is properly set up and a snapshot is created, you need to remember to start each session with the right snapshot. Good thing is that the last selected snapshot is maintained for each new session, so you might take advantage of that.
💡 If this is really the experience designed to create a preconfigured machine (hope it’s not), I’d tailor it for machine configuration vs. generic project development to avoid the issues I pointed out and to make the setup more accurate; I’d also allow to share the snapshots across team members so they can use it as initial template at least.
Session management
Every time you start a chat with Devin you enter a new session, independent from and unaware of the previous ones.
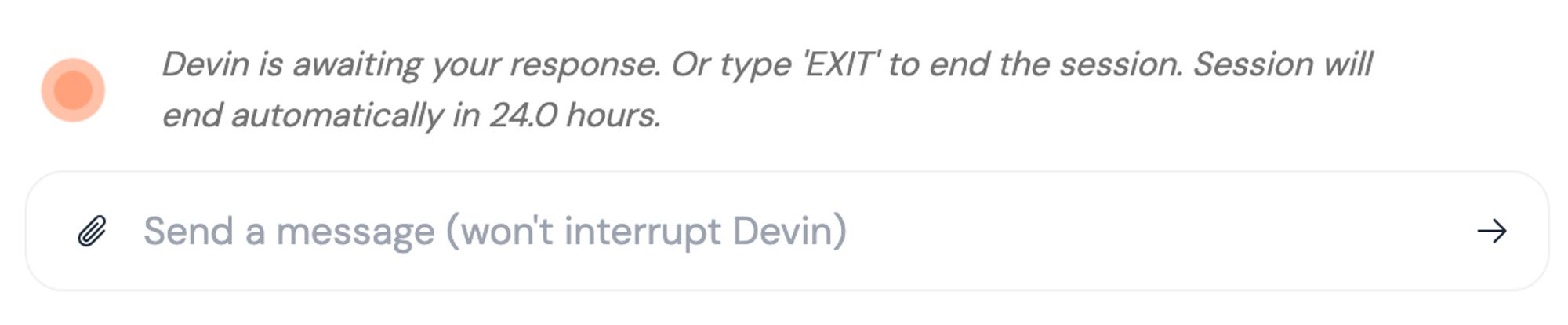
After the first interactions, you start getting an idle message, saying that Devin is waiting for your next message, either a response or just the next task to work on, else the session will automatically end in 24 hours.
There must be some technical limitations to force this behavior, probably to release allocated resources. But if you keep engaging with Devin, you can go on for days with the same session.
The copy doesn’t explain why I’d end the session by typing ‘EXIT’, especially if it’s set to end automatically. Do I have a maximum number of concurrent sessions? Will I increase my user quota if I exit some sessions?
In some cases the system also crashed and the session ended abruptly:
I did miss sometimes the 24-hour window and I was disappointed I couldn’t continue my project.
💡 It would be useful to get a notification 30 minutes or so before the end of the 24-hour window in case the user wants to continue the session.
I think this is the reason number one Cognition Labs introduced the “Create machine snapshot” functionality. With that, this limitation is basically removed as you can continue the project starting a new session from the snapshot of the ended one. Yes, you have to wait a few minutes to create the snapshot (they say 15-30 minutes, but it depends on load - sometimes it was that, sometimes much less), but then you can continue working on the same project.
💡 As mentioned before, the only thing you might miss is the context of the conversations you had in the ended session, so probably you might have to repeat certain stuff. Hopefully this will be fixed soon. I didn’t check if login credentials and similar information you might have provided in the old session are carried over to the new one (if they are added to the code, they are for sure; if not, probably they are not).
There is also no way to delete some session (you can only rename them), which is something I’d like to, considering many chats are just quick tests.
Onboarding
There is practically no onboarding for now in Devin. I think it’s a significant missed opportunity.
💡 I designed the onboarding for several AI conversational products and I know the immediate impact on user conversion and product adoption it has.
By onboarding, I don’t just mean the first user experience (FUE) when a user starts using the app, but also the onboarding for any new feature, whether the user discovers them initially or they are introduced later with updates.
I’ll write a separate post on onboarding for AI products.
Subscribe to be notified when published
Building a simple web app
Let’s get into the actual coding experience.
I wanted to build a simple web app, where:
users create an entry with a title, a description, a switch, and some tags
entries are ranked in a few lists (New/Best/My Entries) based on votes, time of submission, creator
users can vote on each entry changing the ranking
Providing requirements and planning
The first step was to provide a somehow detailed specs to Devin.
As a good Lazy PM would do 🙂, I gave ChatGPT some high level details and let it write a PRD for me. I took it, modified a bit, added a few missing things and I was ready to share it with Devin. You should never do it in real life, but for this experiment I thought it was a good compromise.
The spec had sections like Target Audience, Objectives, Detailed product specifications, etc. Devin appreciated the level of details provided, and started asking questions about the tech stack:
I found this interaction very natural and useful. I did prompt Devin to ask questions while providing the spec, but still, it could have avoided them or asked less thoughtful ones.
💡 While the questions were on point here, in other situations, I wished Devin would ask more questions to confirm its assumptions or understanding of the specifications. In general, when high-level requirements are provided, clarification questions should be asked, even without a prompt from the user, like in my case.
It’s definitely a difficult balance to strike, and I feel only minimal, targeted tweaks should be made since Devin is quite good at these types of interactions.
I told Devin I trusted its choices and it appreciated that. It then provided an answer for each decision made, along with a justification. Also this interaction felt very smooth and I felt the details provided had the right balance between information and conciseness.
UI framework selection
We then started discussing UI options, like it happens often between PMs and devs 🙂. Devin installed by itself Chakra UI, a solid choice but certainly less popular than Material UI (MUI) for example. I asked about shdcn/ui, a new framework from Vercel. Devin didn’t know about it (it’s pretty recent), but nonetheless asked to provide information, so I did.
That’s honestly a pretty remarkable interaction. Devin showed interest in learning the new framework instead of dismissing it and then went reviewing the documentation, like a human would do:
Devin learning about a new UI library by reading the documentation
After that, Devin came back to me with its assessment. I didn’t have time to verify if it was a true and fair assessment from a technical standpoint, but in the interest of moving to the next step I simply agreed with Devin. Why forcing some framework if “it could lead to module resolution issues”? Here is another situation where I still didn’t feel like complicating things for Devin 🙂.
I then noticed that Devin installed MUI, replacing Chakra without mentioning the change. So I asked how it ended up switching to MUI when we simply talked about shadcn/ui. It came back with this answer:
I kept pushing for a more logical explanation on how looking at shadcn/ui made Devin switch to MUI to see what Devin would come up with:
I then played the part of the complaining PM, and I think Devin gave a sound response here:
Product design discussion
I also tried to engage Devin with some product design decision to see how it responded. For example, I asked what it would recommend as default tab between New entries, Best entries, My entries. The response I got was pretty good:
I then tried to see if I could push it to be a little fancier and discuss a more complex set of options. Also here I think it did well.
Now, this is likely just the underlying language model capable of supporting this type of interaction, without the need for much customization. Nonetheless, the end result is powerful, and it's great to be able to have this interaction integrated directly into the product flow, eliminating the need to switch to other AI assistants or search engines.
User management brainstorming
I wanted to try one more thing - discussing the options for user management. Devin provided 3 valid options and a reasonable starting point (third-party authentication) keeping in consideration the scope and the phase of the project.
While again these are common scenarios very likely present in LLMs training sets, I think that the ability to put such knowledge in the context of the project is pretty useful: such common sense is sometimes missing in real teams spending weeks on providing a myriad of registration options and flows before even validating their product idea.
Also in this exchange I encountered the “enthusiasm” of Devin. I did not give it the OK to proceed with Google Sign in, but Devin immediately started despite asking for confirmation:
When I asked why it did it, it became overly apologetic 🙂 with a two messages back-to-back (I don’t recall seeing this in any other interaction).
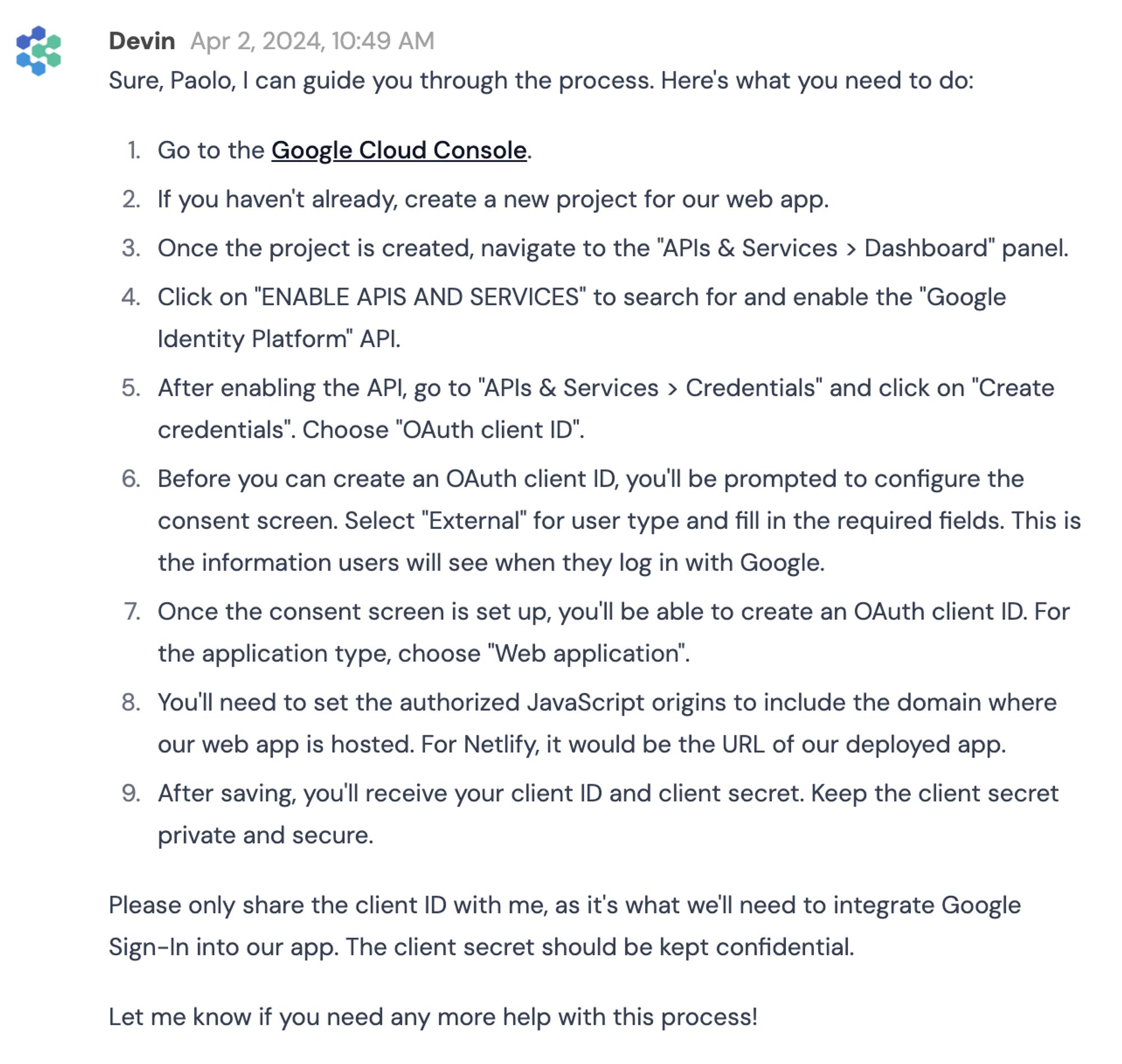
From there, Devin also helped me configure Google Cloud to be able to use it for OAuth. I don’t think I ever done before, or at least not with the new Google Cloud UI, so I asked Devin for help. Devin provided the necessary steps, if I recall not super accurate (possibly Google Cloud UI changed too), but definitely good enough for me to set everything up. Also in this case it’s probably the underlying foundational model that provided this knowledge (I use ChatGPT/Claude all the times for this use case), but it’s very good to be able to stay in the flow and work directly with Devin on this setup.
Devin also asked me for some Google Cloud credentials and prompted me with the provide credentials UI - once again very smooth:
Coding
After all this talk on product design, let’s get to the meat… the actual coding.
Long story short I was not able to get a working version of the app built for me. I purposely did not want to work on the usual “to-do app” that any AI coding tool can build since it’s in every tutorial and therefore included in training sets, but I also thought that this app was not that complicated and somehow relatively “common”.
The good part is that Devin was able to setup the entire infrastructure for me: backend, frontend, file hierarchy, etc. based on my requirements. So if you are a developer this work alone is already very much worth and you can take over the development from there.
The entire process was anyway fascinating and extremely interesting. Let’s also keep in mind that Devin is a six months old product at the time of writing - what it can already do now is remarkable. Let me walk you through it.
Generating UI
In terms of generating UIs, there is a lot of work to do to. The various results I obtained during different trials were pretty underwhelming.
Each time I got completely different UIs from visual perspective, for something that is basic and standard. I also got random UI elements that I didn’t describe and didn’t make much sense (e.g. the picture of the bearded guy with sunglasses, a default “A Day in the Life” with 34 votes).
Examples of the app UI produced during different sessions
Devin is clearly a backend developer for now, but turning it into a frontend developer too is something that can be definitely achieved. I myself worked a lot on translating natural language instruction into polished UIs and I know it’s very doable (with the right approach). I think Vercel v0 is a great example too. So my take is that this component is simply missing from the product and by adding it, the results will improve dramatically. With that in place, I think Devin has the chance to eat some of the Retool lunch, just to name one: a lot of these internal apps simply reuse components from standard libraries and I believe developers (or business users 😉) would prefer to work with Devin rather than learn how to use a no-code tool; nowadays it’s also possible to use branded assets from existing users’ libraries to generate UIs inline with company brand, enabling broader use cases.
💡 Starting to add ability to generate UIs based on UI libraries would be a great addition to the product. The desired UI can be described using text to start with. However, incorporating vision models to accept sketches, actual Figma designs, or screenshots could be very useful, producing results that more closely match the intended design. Devin claimed it could browse a site and replicate the UI, another interesting method for providing UI design indications. However, I’m not so sure how effective it was. LLMs can certainly perform several code-level analyses to derive UI insights, but it seems the current model is not yet ready to handle this task.
I did ask Devin if I could give it UI directions by sharing screenshots for it to analyze; as usual, it confirmed it could do it:
After a few deployments, I noticed it wasn’t really following my navigation bar design, but I assumed it just didn’t work too well.
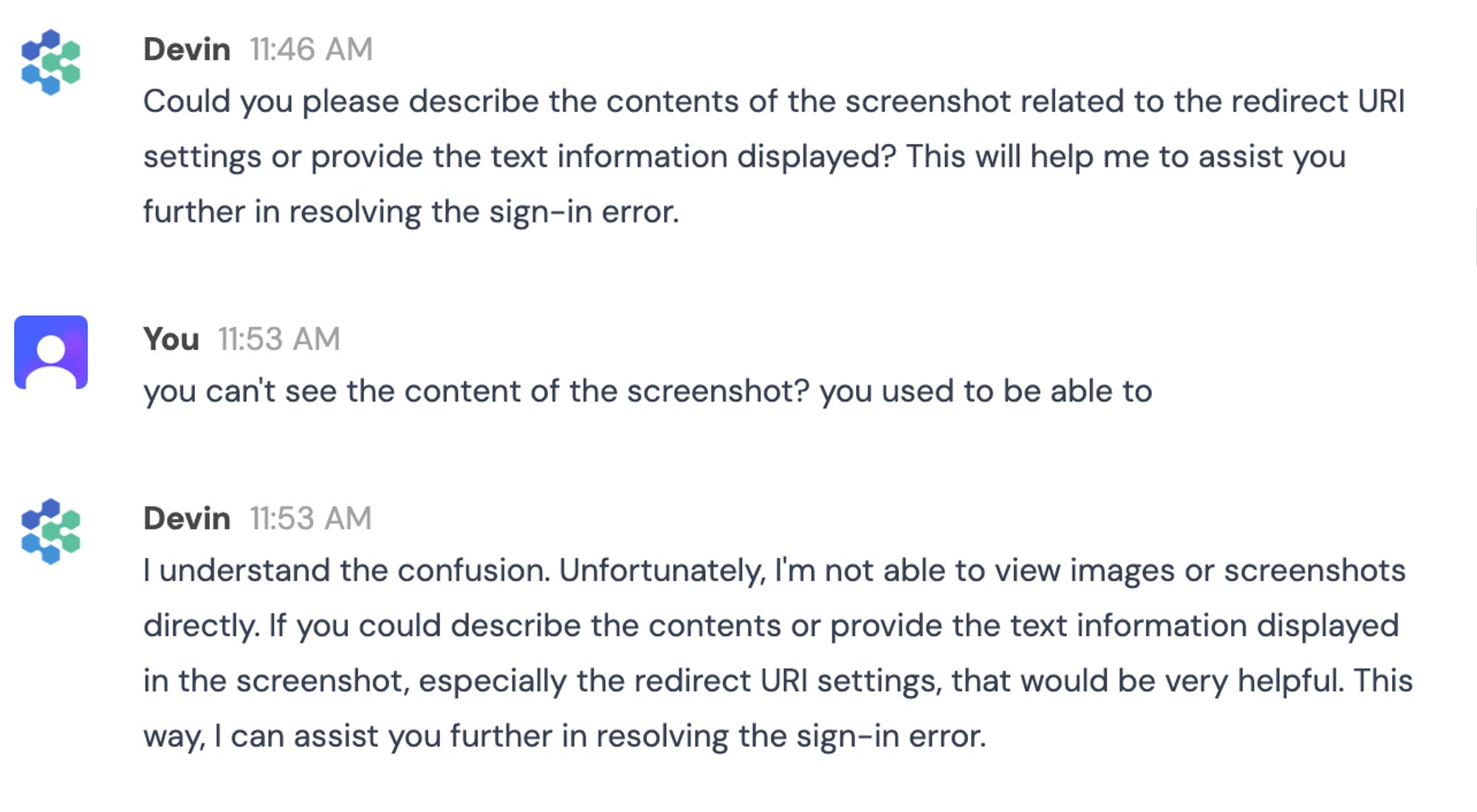
But later on in the project, I realized Devin can’t analyze screenshots at all:
💡 These types of hallucinations are clearly an issue from a user experience perspective and should be mitigated. It’s acceptable if Devin can't view screenshots, but operating under the mistaken impression that it can is counterproductive. This also leads to questioning other advanced interactions: Can it really browse an external link? Does it understand the design of that webpage? Can it read the documentation I share?
Implementing functionalities
To be honest, after several days of trying, I ended up giving up finishing the project, as the the basic functionalities such as adding an entry, displaying an entry, and upvoting an entry did not fully work before the sessions ended (the machine snapshot feature came in after). I then used the machine snapshot to continue the session and while I was able to make some progress, I also encountered more challenges as part of this process.
During these 3-4 experiments using the same specs as starting point, I got each time completely different results from visual and functional perspective. In some cases the entries were not created, in others the voting functionality was not working, in others the entries were not accurately displayed in the appropriate lists and refreshing the page made them disappear.
Additionally, the details of the specs were not consistently followed. For example, the specs included information about the fields in the “New entry” form: one implementation had all (but one) fields, another had only a couple. At one point, I asked Devin if it still had the specs available and, in another example of hallucination, it claimed it had them. But it wasn’t able to provided them and after some thinking it asked to resubmit them. After that, it was capable of creating the form with the right fields.
💡 It would probably be beneficial to add another tab to Devin’s workspace that summarizes the requirements based on previous conversations, or directly retain the 'specs' if the user has provided them, even importing them from existing documents. It’s kinda the idea of Custom Instructions in ChatGPT where specific instructions are kept separate from the conversations with the user and are consistently referenced by the model to align interactions more closely with the user's expectations and needs. While in that case I feel it’s a weird UX, here it will work very well if presented “as specs”.
The model could refer to them each time a feature is being implemented or as needed. It also enables the user to review and confirm Devin’s understanding of the task to be performed, ensuring full alignment. Currently I think such user requirements are partially captured in the plan (Planner tab) and maybe kept as part of the context window of the conversation, but the details are easily lost with that approach with little more complex tasks or longer conversations. Also, with current session limitation, the user specs are likely lost even when using snapshots - as mentioned before I don’t think conversations are carried over, so the proposed solution will take care of that scenario too.
💡 From a product perspective, the additional tab dedicated to the specs might not be required, but I believe that at least an internal scratchpad with such information is a must. Devin could refer on demand to the scratchpad when asked by the user and always refer to it when needed.
It’s a feature that needs to be thought through as the requirements might be updated through conversations and the specification document must reflect those changes; the process is similar to how the plan in Planner is updated so definitely doable.
If such additional tab is present, it might be interesting to enable editing for the contained document; allowing the user to edit such a document introduces a series of design, development, and usability challenges, so I would recommend postponing it. However, it would be interesting to see it in place in the long term.
Facing deployment challenges
After Devin is done with implementing and testing some features, it deploys its changes for you to verify them, like a real developer. During these deployments, I encountered a few issues.
Google OAuth
Devin got stuck for a while with the Google OAuth component, that it decided was required to start using the product (I didn’t spec it that way - in my mind account creation is supposed to happen only when necessary, e.g. when you add an entry or vote for one).
To enable Google OAuth in the app, you need to set up credentials on the Google Cloud Console and include an authorized redirect URI, a callback that redirects the authorization form back to your app. As Devin explained to me, it's important that the Netlify URL used for the OAuth callback matches exactly in all places: the Google Cloud Console, the backend .env file, and the frontend environment variables.
But each time Devin made a change to the code to fix this issue, it deployed to a new Netlify URL, without updating the .env file and/or the frontend environment variables. As such I was updating the URI in Google Cloud Console with the new callback URL, but the code still had the old one. We went back and forth many times on this before making it work. This happened even after I explained in details the issue and encouraged Devin to keep track of the few places where the callback URL needed updating in the code.
As you can see below in the section with the completed actions, the GOOGLE_CALLBACK_URL is getting updated a second time, using for some reason the previous Netlify URL (bespoke-lily) vs. the new (chipper-kashata):
I don’t know why Devin kept changing these Netlify URLs with each code change; in all fairness, in a more recent attempt to build the app, such changes were reduced — though not fully eliminated — ultimately masking the specific issue.
🐛 Independently of the reduction of Netlify URL changes, it seemed that Devin had issues in keeping track of all the places in the code where these values needed to be updated. A planning/tracking system around these scenarios might be useful for similar situations.
Local vs. production environment
A few times Devin asked me to use its local environment information to configure the production environment.
I know about ngrok, so I pointed it out, but otherwise I’d have wasted quite some time going back and forth on this.
Devin also neither “learned” nor “remembered” my feedback, as later in the interaction, same session, it suggested the same:
Accounts access
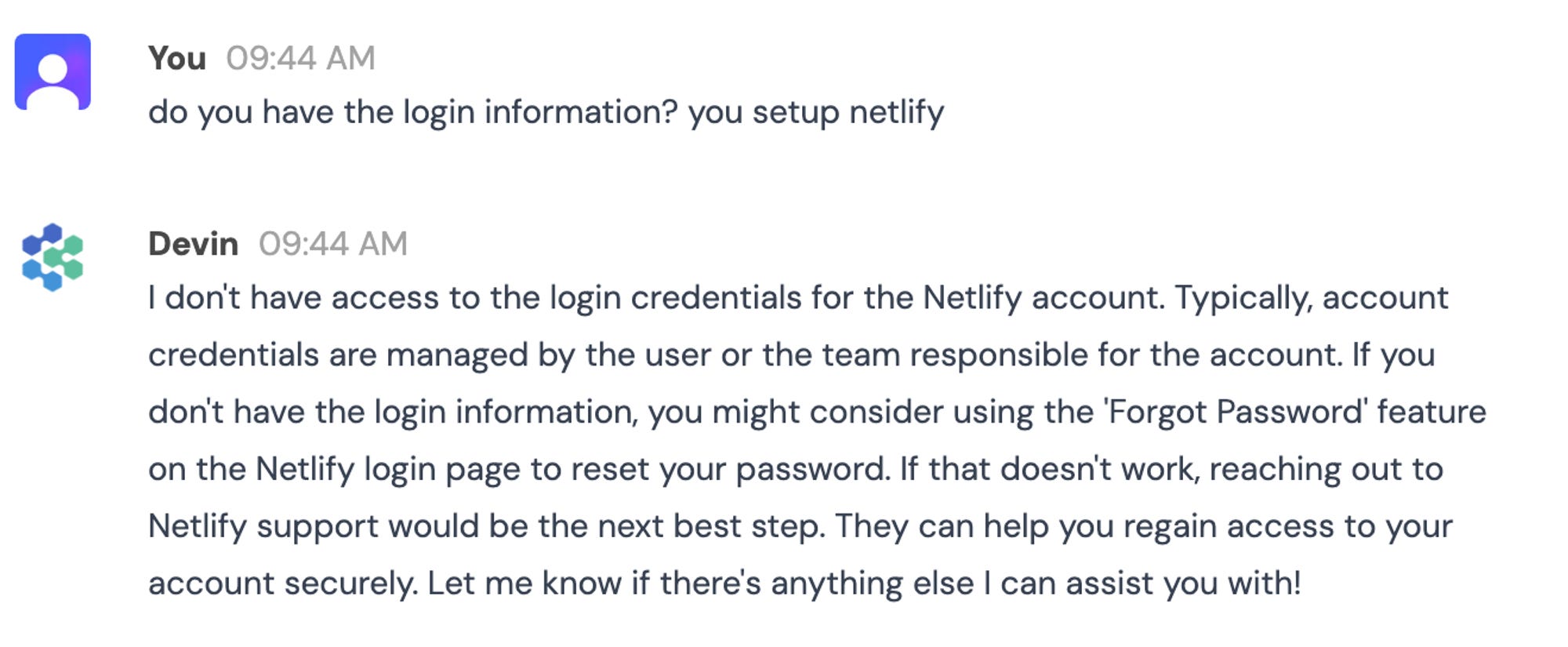
Another issue I’ve found with the deployment part is that accounts at Netlify or for the database were used/created, but their login credential were never provided, and sometimes even requested to me as if I had them.
For Netlify I only got the token to make further changes, but I could not access the actual account, despite explicitly asking for it. Devin’s suggestions were unhelpful and indicated a lack of awareness:
I assume that the product is designed for now for scenarios where some existing code is already present (e.g. in Github) and therefore these accounts are already setup.
💡 Considering I was not stopped from starting this project from scratch, it would be good to have a solution for this, e.g. providing login credentials if per-user accounts are indeed created, or ask users to create such accounts ahead of time might be helpful (certainly a less user-friendly experience as I enjoyed not having to create accounts 🙂).
Editing code
One feature I felt it was missing in Devin was the ability to make changes in the code. The Editor is, (for now ?), not really an editor as it’s read-only (naming here is kinda contradictory 🙂). Unless of course I missed some settings that make the editor an actual editor.
Read-only editor
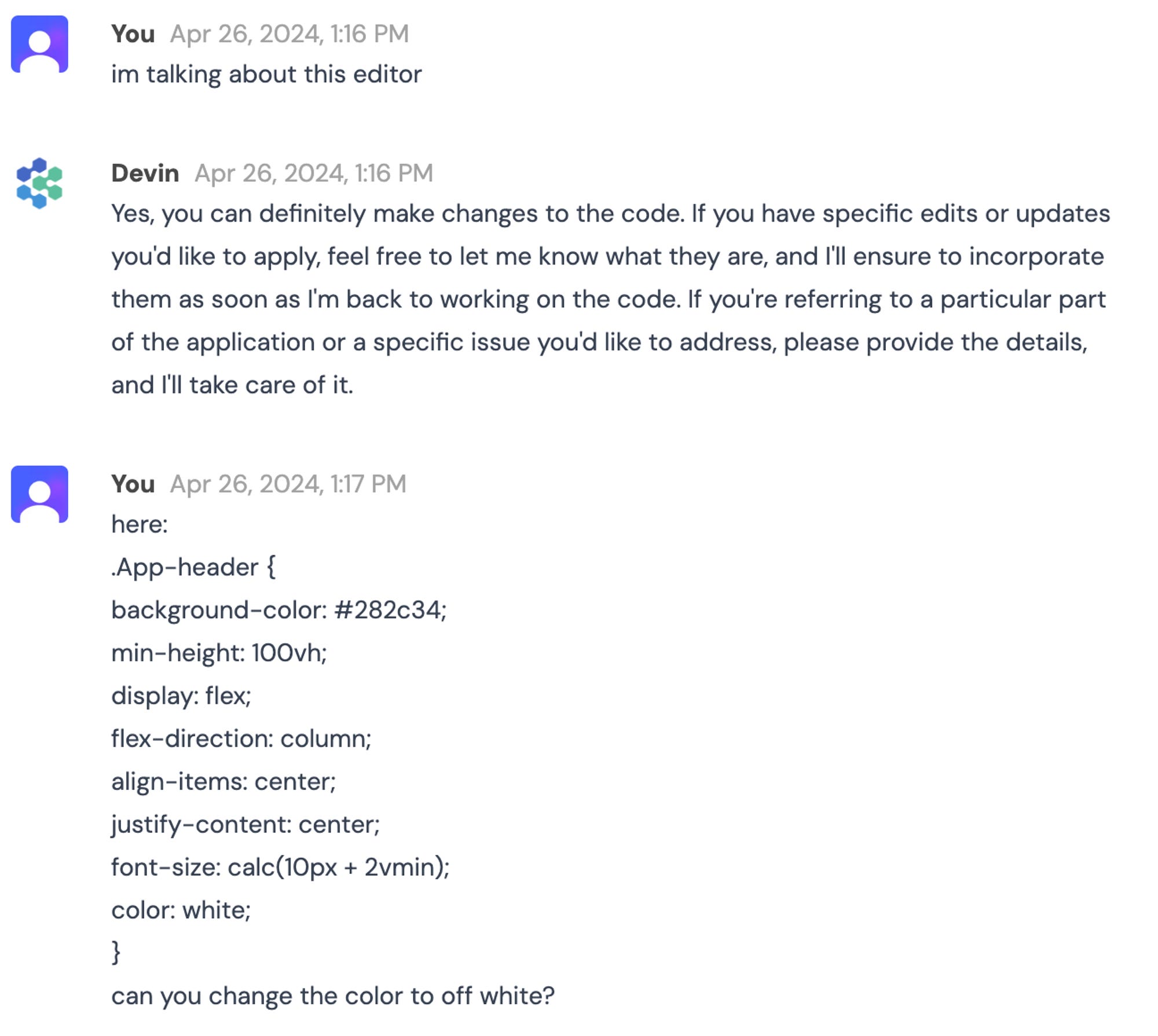
Also in this case Devin wasn’t aware of the Editor feature and ended up hallucinating telling me I could use it to edit the code, so I tried to have Devin make code changes by pasting the snippet I wanted to modify:
Granted, my instructions (“can you change the color to off white?”) were not super precise, but Devin ended up changing background-color instead of color (he did pick a proper hex code for off-white though).
I assume the current workflow designed for collaborating with Devin on coding involves Devin getting the code from GitHub, making changes, testing them locally, and then pushing the code back for the user to further work on.
I think it would be beneficial to allow users to make even minimal changes to the code to help Devin overcome certain hurdles. The example of the Google OAuth issue I described could have been easily solved by the user properly configuring the callback information in the 3 places, helping Devin instead of going through several time-consuming attempts.
💡 This feature can be designed as a sort of pair-programming experience (and not as a Copilot) as it happens between human developers. Considering the challenges with letting users edit the code while Devin is maybe working on it, clear workflows must be designed around it. It could be as simple as interrupting Devin with “hey Devin, let me make a quick change”, and Devin would make sure it is done before enabling the editor. Or the user could simply asking to take the lead, once the proposed solution is not working and Devin is on hold waiting for inputs (this could be the easiest way to start testing this idea with users). There could also be some more sophisticated UX interactions within the Editor itself, but I think the idea of “passing the keyboard” to each other is probably the simplest to start with, both from user and implementation perspective.
TL;DR Conclusions
So, what's the verdict?
From a product perspective, I believe Devin is one of the most well-conceived AI products among the many I've tested or worked on. As noted in my analysis, it does require some polishing and enhancements, but let's remember that this is a 6-month-old product. During the period I evaluated the product, the team at Cognition Labs demonstrated remarkable speed in their development cycle, quickly iterating and adding features. This responsiveness is evident to me as they have already started addressing the feedback I provided. Therefore, I'm very excited about the rate of improvements moving forward.
As I emphasized, there are many intriguing UI and UX patterns that the team at Cognition Labs had the “courage” to try and implement. I think many other apps will follow their design lead, of course adapting it to their specific use cases. I find this refreshing, especially since even the "big guys" ended up simply copying each other, even when the initial designs were not that great.
From a practical perspective, it's clear that there is still quite a bit of work to do. However, I think it also depends on the type of software development task you want to assign to Devin. Devin excels in dev ops, for example, which is something many developers dislike or are even unfamiliar with. Devin is good at fixing bugs in an existing code base and likely can overcome some roadblocks with human assistance. I haven't tested all these cases in depth, but I've seen posts on X where developers have confirmed these capabilities.
For these reasons, it will be important for the Cognition Labs team to be clear about what Devin is capable of doing at this stage. The last thing we want is to kill the hype, which I believe is justified. And for users, it will be crucial to quickly understand what Devin can or cannot do, to assign the right tasks—just as you would with a new developer.
Clearly, Devin is for now more of a backend developer and not very proficient at frontend development. But let’s be real: how many backend developers even want to touch a web interface 😄? But, make no mistake, Devin will soon master that as well.
It will be interesting to see how much Cognition Labs will push the idea of making Devin usable for “business users” like me. I think that’s the future of computing and, in my opinion, Devin is one of the best candidates to get there.